前言
在《Robots.txt 使用指南:网站 robots.txt 文件配置方法详解》中我们讲解了可以使用 robots.txt 文件来禁止搜索引擎的网络蜘蛛抓取网站内容。
但是该方法也并非对所有搜索引擎都有效,而且也有实现不了的效果,比如禁止传递链接权重、禁止快照等。
本文就继续介绍下如何通过 meta 标签彻底禁止搜索引擎收录和索引网站的指定网页内容。
禁止搜索引擎收录和索引指定网页内容
meta 标签(漫游器元标记)是网页 HTML 语言标记的一种,可以让我们更精确地控制网页如何被编入搜索引擎的索引并在搜索引擎结果中显示。
使用方法
将编辑好的 meta 标签放在目标网页的 <head> 部分即可,示例如下:
1 2 3 4 5 6 7 8 9 | <!DOCTYPE html> <html> <head> <meta name="robots" content="nofollow"> <meta name="googlebot" content="noindex, nofollow"> …… </head> <body>……</body> </html> |
name:指生效的目标抓取工具(网络蜘蛛),robots 表示全部蜘蛛,也可以指定单个蜘蛛,如 Googlebot;content:操作效果,noindex 表示不编入索引。
指令和效果说明:(截图自 Google Developers)
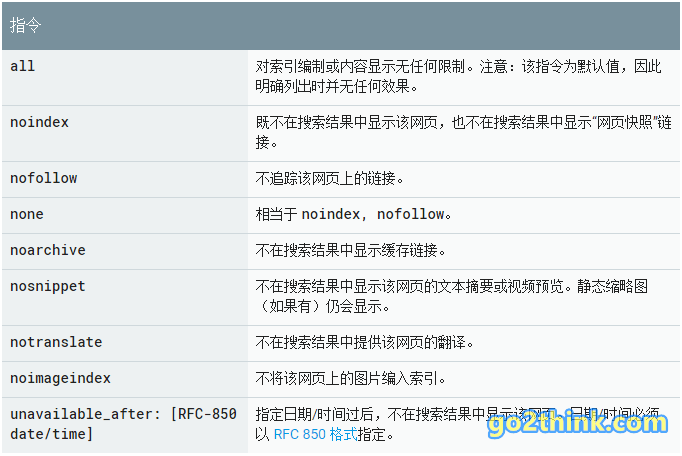
常用代码示例
1、禁止所有搜索引擎的收录和索引,也不追踪网页上的链接:
1 | <meta name="robots" content="noindex, nofollow"> |
2、只禁止谷歌和百度蜘蛛的收录和索引:
1 2 | <meta name="googlebot" content="noindex"> <meta name="baiduspider" content="noindex"> |
3、允许搜索引擎收录,但不追踪网页上的链接,也不传递链接权重:
1 | <meta name="robots" content="nofollow"> |
4、允许搜索引擎收录,但禁止显示网页快照:
1 | <meta name="robots" content="noarchive"> |
5、允许搜索引擎收录,但禁止索引网页上的图片:
1 | <meta name="robots" content="noimageindex"> |
现在很多 SEO 插件,如 WordPress 的 Yoast SEO 等都支持在文章编辑页面直接设置索引方式,非常方便。
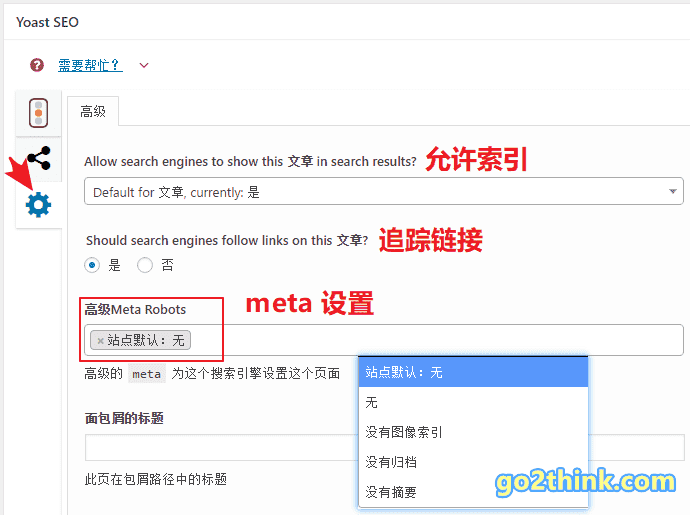
结语
在网页的 <head> 标签中插入好 meta 标签后,并不会立即生效,需要等到下一次搜索引擎抓取该网页时才会更新状态。
对于常见的 WordPress、Typecho 等博客平台,通常使用如 header.php 等模版统一生成 <head> 标签,会对网站全部内容都生效,需要格外注意。最好使用插件对单篇文章进行设置。
参考资料:
Go 2 Think 原创文章,转载请注明来源及原文链接
